1. 영화 제목 '매트릭스' 의 평점을 가져오기
->find_one() 사용
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
# insert/ find/ update/ delete
matrix=db.movies.find_one({'title':'매트릭스'})
print (matrix['star'])
2. 영화 제목 '매트릭스' 와 평점이 같은 영화 제목들을 가져오기
->find()와 for문 사용
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
# insert/ find/ update/ delete
target_movie=db.movies.find_one({'title':'매트릭스'})
target_star=target_movie['star']
movies=list(db.movies.find({'star':target_star}))
for movie in movies:
print(movie['title'])
3. 영화 제목 '매트릭스'의 평점을 0으로 만들기
->update_one() 사용
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
# insert/ find/ update/ delete
db.movies.update_one({'title':'매트릭스'},{'$set':{'star':0}})
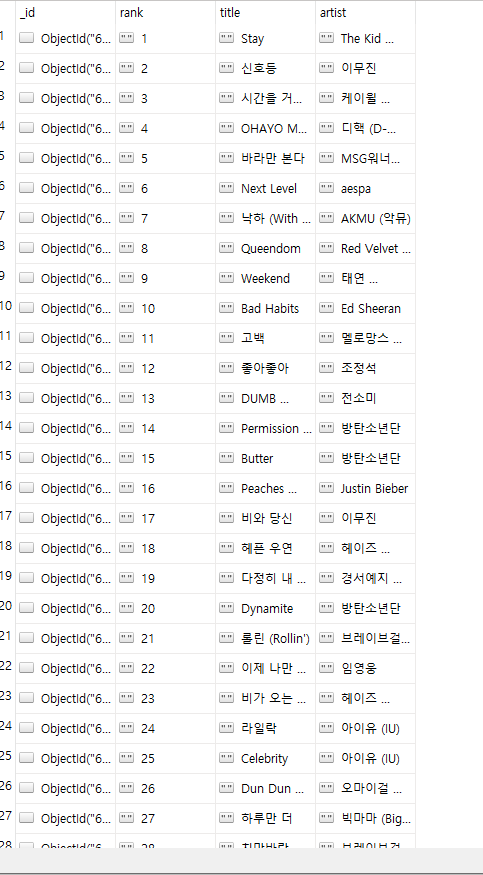
4. 지니뮤직 사이트 크롤링하기
-strip()을 사용해서 공백제거
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=D&rtm=Y',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs=soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for tr in trs:
a_tag=tr.select_one('td.info > a.title.ellipsis')
if a_tag is not None:
rank=tr.select_one('td.number').text[0:2].strip()
title=a_tag.text.strip()
artist=tr.select_one('td.info > a.artist.ellipsis').text
doc={
'rank':rank,
'title':title,
'artist':artist
}
db.music.insert_one(doc)
print(rank, title, artist)
'웹' 카테고리의 다른 글
| 18. 모두의 북리뷰 페이지 만들기 (0) | 2021.09.06 |
|---|---|
| 17. flask (0) | 2021.09.05 |
| 15. pymongo로 DB조작하기 (0) | 2021.09.03 |
| 14. 웹스크래핑 연습 (0) | 2021.09.02 |
| 13. 웹 크롤링 (0) | 2021.09.01 |



댓글